RoLID-11K:首个基于行车记录仪的大规模路边垃圾检测数据集
本研究成果已发表于 WACV 2026 Workshop。
路边垃圾不仅破坏环境,还带来安全隐患和高昂的清理成本。然而,目前的垃圾监测主要依赖耗时费力的人工巡查和公众举报,覆盖范围极其有限。为了解决这一痛点,我们推出了 RoLID-11K —— 首个专门针对行车记录仪视角下路边小目标垃圾检测的大规模数据集。
为什么需要 RoLID-11K?
现有的垃圾检测视觉数据集主要集中在街道静态图片、无人机航拍或水下环境。它们无法反映行车记录仪(Dashcam)画面的独特性:在车辆行驶过程中捕捉到的垃圾往往极其微小、分布稀疏,并且隐蔽在杂乱的路边背景中。
相比之下,行车记录仪成本低廉且普及率极高。如果能利用这些已经在不断记录的视频数据,实现被动的路边垃圾监测,将是一种极具潜力的低成本、可扩展方案。
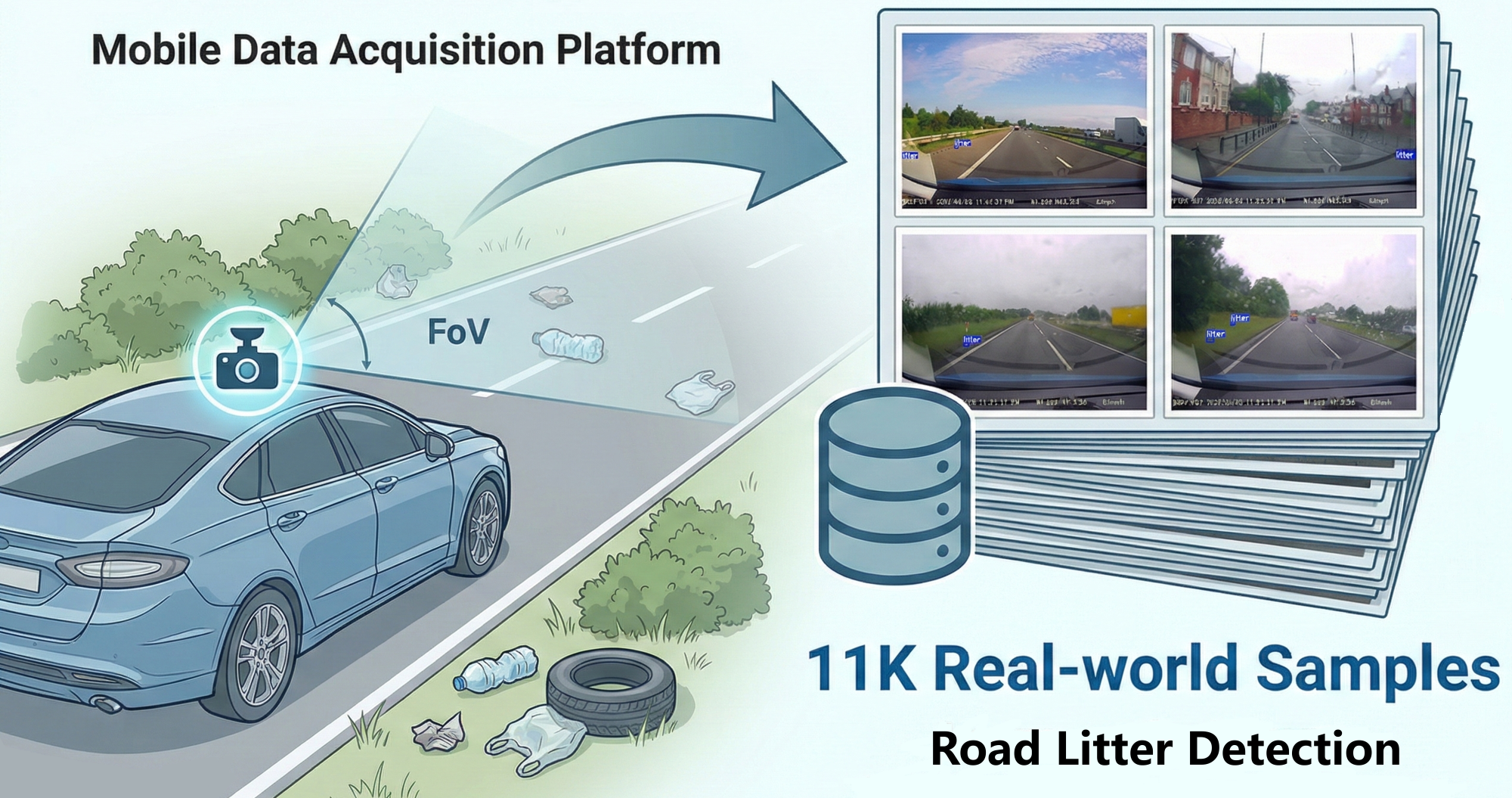 图 1:RoLID-11K 数据集概览。车辆配备行车记录仪作为移动数据采集平台,在多样的真实路况下捕捉路边垃圾。
图 1:RoLID-11K 数据集概览。车辆配备行车记录仪作为移动数据采集平台,在多样的真实路况下捕捉路边垃圾。
数据集亮点与挑战
RoLID-11K 包含了在英国各种驾驶环境(乡村道路、郊区街道、双车道和城市环境)以及不同天气、光照条件下拍摄的 11,000 多张标注图像。它为目标检测模型带来了极大的挑战,主要体现在:
- 极端长尾分布:大部分图片中只包含 1 到 3 个垃圾目标。
- 小目标主导:根据 COCO 数据集的评估标准,测试集中高达 86.8% 的标注对象都属于小目标(面积小于 )。
- 空间分布偏差:由于英国是靠左行驶,垃圾也更容易在风力等作用下聚集在左侧路沿,导致目标的出现位置存在明显的空间倾向性。
基准测试结果:精度 vs 速度
为了评估现有检测器在这个具有挑战性的数据集上的表现,我们对一系列现代目标检测模型进行了基准测试,涵盖了从注重精度的 Transformer 架构到注重速度的实时 YOLO 系列。
Transformer 架构表现最佳
| 模型 | 主干网络 | |||||
|---|---|---|---|---|---|---|
| CO-DETR | ResNet-50 | 79.2 | 32.1 | 31.2 | 37.5 | 40.0 |
| DINO | ResNet-50 | 78.5 | 31.5 | 30.9 | 36.1 | 11.2 |
| DEIMv2 | ViT-Tiny | 74.3 | 27.8 | 27.4 | 30.3 | 21.7 |
| RT-DETR | ResNet-50 | 73.9 | 28.9 | 28.3 | 32.1 | 18.5 |
| DiffusionDet | ResNet-50 | 67.0 | 24.5 | 24.3 | 26.7 | 9.6 |
CO-DETR 在整体 上表现最佳,证明了其密集的 Transformer 分配机制能为极小和稀疏的垃圾实例提供最可靠的定位。DINO 表现同样出色。而 DiffusionDet 在该数据集上表现不佳,这表明其粗糙的去噪过程可能难以应对嵌入在杂乱背景中的微小目标。
实时模型(YOLO 系列)的局限性
| 模型 | |||||
|---|---|---|---|---|---|
| YOLOv8 | 50.1 | 17.5 | 16.6 | 22.9 | 6.0 |
| YOLOv9 | 50.8 | 17.1 | 16.0 | 23.5 | 4.0 |
| YOLOv10 | 49.7 | 17.4 | 16.3 | 23.2 | 5.1 |
| YOLOv11 | 52.1 | 18.3 | 17.2 | 24.6 | 5.7 |
| YOLOv12 | 51.6 | 17.7 | 16.9 | 23.3 | 15.1 |
YOLO 模型虽然能够实现亚毫秒级的推理速度,但在 上落后于 Transformer 架构,特别是在中等目标()的定位上差距明显。这证实了轻量级的检测头和较低的输入分辨率,限制了它们对极小目标的精确定位能力。
总结
实验结果表明,虽然 Transformer 架构的检测器提供了最强的定位性能,但它们高昂的计算成本限制了在低功耗平台上的实时部署。相反,YOLO 模型虽然推理极快,却难以捕捉检测小尺寸垃圾所需的精细空间细节。
RoLID-11K 清晰地揭示了这些局限性,它为开发能够应对真实动态驾驶环境中极端小目标的检测系统设定了具有挑战性的基准。
📄 想要了解完整的实验数据与具体细节? 点击此处下载 WACVW 2026 完整版论文 PDF