RoLID-11K:The First Large-Scale Dashcam Dataset for Roadside Litter Detection
This research was published at the WACV 2026 Workshop.
Roadside litter poses environmental, safety, and economic challenges, yet current monitoring relies heavily on labor-intensive surveys and public reporting, providing limited spatial coverage. To address this gap, we introduce RoLID-11K, the first large-scale dataset specifically designed for roadside litter detection from dashcams.
Why RoLID-11K?
Existing vision datasets for litter detection focus on street-level still images, aerial scenes, or aquatic environments. They do not reflect the unique characteristics of dashcam footage, where litter appears extremely small, sparse, and embedded in cluttered road-verge backgrounds.
In contrast, dash cameras are inexpensive and widely used. Their ubiquity presents a practical opportunity for passive roadside-litter monitoring using video that is already being recorded, offering a highly scalable and low-cost solution.
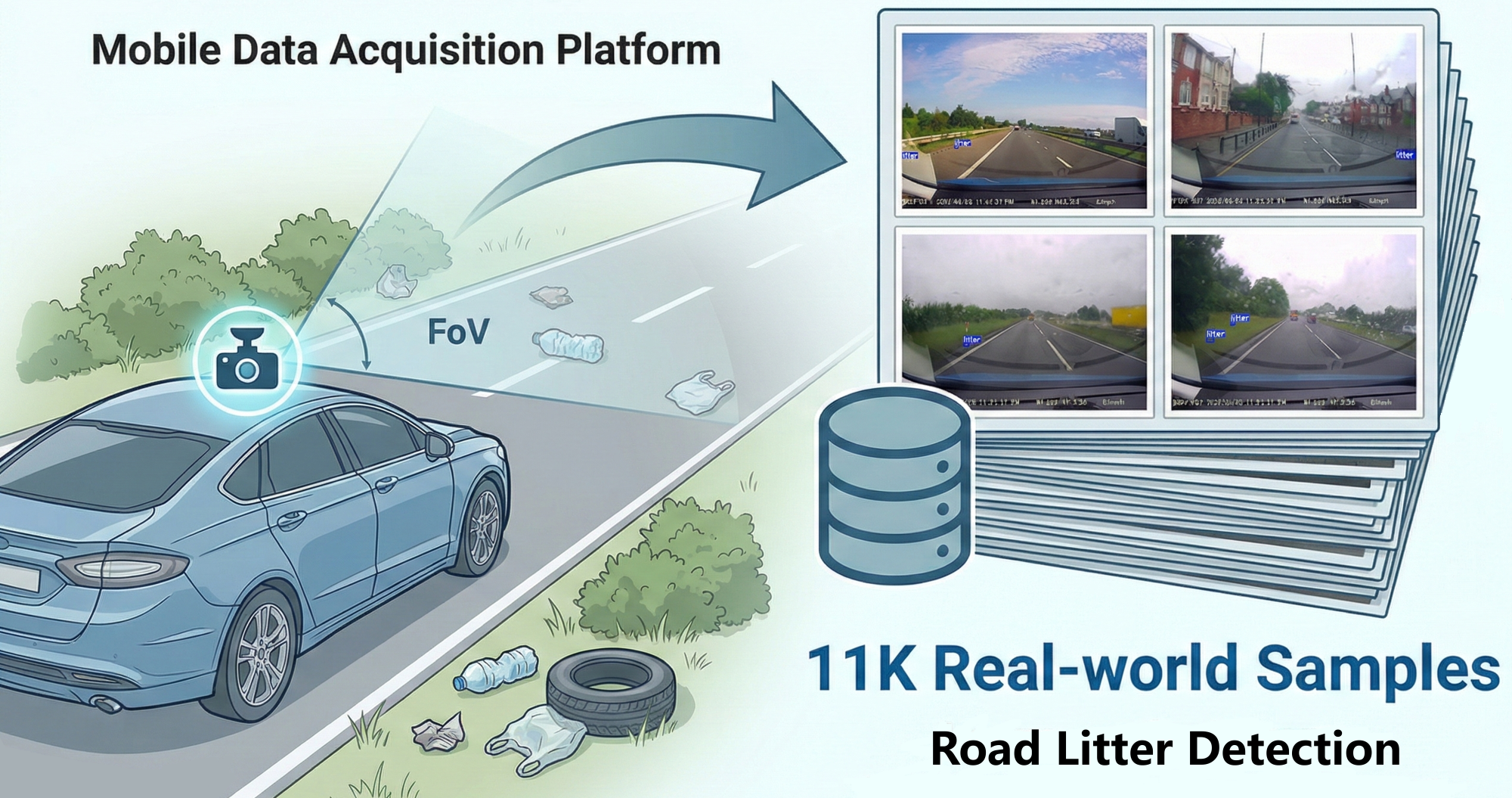 Figure 1: Overview of the RoLID-11K dataset. A vehicle-mounted dashcam serves as a mobile data acquisition platform, capturing roadside litter under diverse real-world driving conditions.
Figure 1: Overview of the RoLID-11K dataset. A vehicle-mounted dashcam serves as a mobile data acquisition platform, capturing roadside litter under diverse real-world driving conditions.
Dataset Highlights & Challenges
RoLID-11K comprises over 11,000 annotated images spanning diverse UK driving conditions (rural roads, suburban streets, dual carriageways, and urban settings) across various weather and lighting environments. It presents severe challenges for object detection models:
- Extreme Long-Tail Distribution: Most images contain only one to three instances of litter.
- Small-Object Dominance: Following COCO evaluation criteria, a staggering 86.8% of the annotated objects in the test set are classified as small (area < ).
- Spatial Distribution Bias: Since driving in the UK is on the left, litter tends to accumulate on the left verge due to driver behavior and wind-driven displacement, creating a strong spatial bias.
Benchmark Results: Accuracy vs. Efficiency
To evaluate performance under these demanding conditions, we benchmarked a broad spectrum of modern detectors, ranging from accuracy-oriented transformer architectures to real-time YOLO models.
Accuracy-Oriented Transformers
| Method | Backbone | |||||
|---|---|---|---|---|---|---|
| CO-DETR | ResNet-50 | 79.2 | 32.1 | 31.2 | 37.5 | 40.0 |
| DINO | ResNet-50 | 78.5 | 31.5 | 30.9 | 36.1 | 11.2 |
| DEIMv2 | ViT-Tiny | 74.3 | 27.8 | 27.4 | 30.3 | 21.7 |
| RT-DETR | ResNet-50 | 73.9 | 28.9 | 28.3 | 32.1 | 18.5 |
| DiffusionDet | ResNet-50 | 67.0 | 24.5 | 24.3 | 26.7 | 9.6 |
CO-DETR achieves the highest overall , confirming that dense transformer-based assignment mechanisms provide the most reliable localization for extremely small and sparse targets. DINO performs competitively. However, DiffusionDet underperforms, suggesting its coarse denoising schedule struggles with tiny objects embedded in cluttered backgrounds.
Limitations of Real-Time Models (YOLO)
| Method | |||||
|---|---|---|---|---|---|
| YOLOv8 | 50.1 | 17.5 | 16.6 | 22.9 | 6.0 |
| YOLOv9 | 50.8 | 17.1 | 16.0 | 23.5 | 4.0 |
| YOLOv10 | 49.7 | 17.4 | 16.3 | 23.2 | 5.1 |
| YOLOv11 | 52.1 | 18.3 | 17.2 | 24.6 | 5.7 |
| YOLOv12 | 51.6 | 17.7 | 16.9 | 23.3 | 15.1 |
While YOLO models achieve sub-millisecond inference latency, they lag significantly behind transformer architectures in , particularly missing the mark on medium objects (). This reinforces that lightweight detection heads and lower input resolutions limit fine-grained localization on very small targets.
Conclusion
Our benchmark reveals a clear trade-off: while accuracy-oriented transformer detectors provide the strongest localization performance, their computational cost limits real-time deployment on low-power platforms. Conversely, YOLO models provide extremely fast inference but struggle to capture the fine spatial details required for consistent small-object detection.
RoLID-11K establishes a challenging benchmark for extreme small-object detection in dynamic driving scenes, aiming to support the development of scalable, low-cost systems for roadside-litter monitoring.
📄 Looking for complete experimental data and technical details? Click here to download the full WACVW 2026 Paper PDF